Loading Complexity
Updated OpenReview paper
Deterministic routing for efficient transformers.
COMPLEXITY-DEEP now focuses on lexical token routing, Zipf-balanced expert assignment, and a shared lexical expert — with corrected matched-budget scaling evidence.
routing table
Token → expert, no learned router
8,078
tok/s sustained
306.5M
iso-param run
−0.0163
final loss gap
Token
token_id
Balance
Zipf freq
Dispatch
expert e
Result
TR < Dense
The corrected 300M run is evaluated at matched tokens over an 8B FineWeb-Edu budget; the 187M model provides the vLLM throughput benchmark.
Current paper story
// SOURCE OF TRUTH
Deterministic routing, shared experts, corrected scaling.
The site now tracks the new OpenReview submission instead of the older architecture story. The message is simple: fixed lexical routing can produce useful specialization without learned MoE routing machinery.
Lexical, deterministic routing
Every token is assigned from a fixed routing table. No learned gating network, no router collapse, no auxiliary balancing loss.
Shared lexical expert
A dense shared MLP path preserves common syntax and language structure while routed experts specialize on lexical partitions.
Corrected scaling evidence
The headline quality result is a 306.5M iso-parameter, iso-batch comparison over 8B FineWeb-Edu tokens.
Late-run advantage
Token-Routed first wins at logged train step 740 and finishes with a −0.0163 smoothed final train-loss gap.
Claims kept precise
The homepage separates benchmark, scaling, and caveats.
- 300M result is quality-at-matched-tokens, not a pure speed benchmark.
- 187M vLLM benchmark reaches 8,078 tok/s sustained on RTX PRO 6000.
- Expert utilization remains near-balanced at the end of the corrected 300M run.
// PROJECTS
Production-grade research artifacts
Explore the architecture, inference engine, model releases, and papers behind the Complexity stack.
Pacific-i64
Available1.5B parameter language model trained with Complexity-Deep routing experiments and token-routed experts.
LLM1.5BF32HuggingFace
OpenReview — Submission
ActiveOur latest OpenReview submission on deterministic lexical routing, shared experts, and corrected Token-Routed scaling.
PaperOpenReviewPeer Review
// INFERENCE
Inference + corrected scaling
8,078 tok/s sustainedRTX PRO 6000 96 GB100 concurrent requestsTTFT 29.3 ms
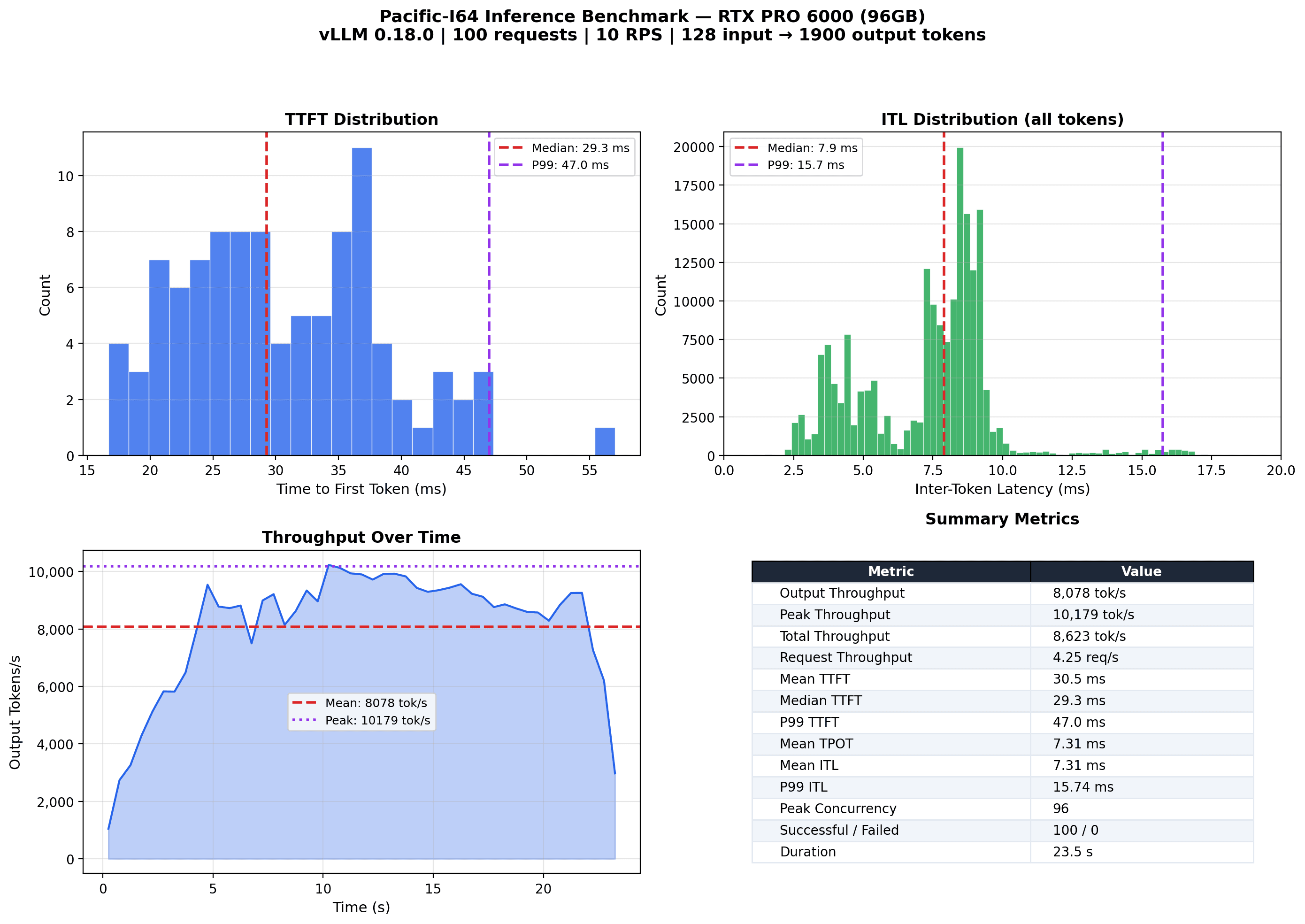
187M Token-Routed model served via vLLM 0.18 with PagedAttention and CUDA graphs. The updated paper also reports a corrected 300M iso-parameter comparison over 8B FineWeb-Edu tokens: Token-Routed first wins at step 740 on train loss, step 750 on validation loss, and ends with a −0.0163 smoothed train-loss gap.
// EXPERT ANALYSIS
Expert analysis
The updated paper emphasizes functional specialization measured by per-expert perplexity on assigned token subsets; geometric separation alone is not treated as proof of specialization.
// PUBLICATIONS
Research
COMPLEXITY-DEEP: Deterministic Lexical Routing with Token-Routed MLP
Anonymous
Submitted to Transactions on Machine Learning Research • 2026
We present COMPLEXITY-DEEP: Token-Routed MLP with deterministic lexical routing, Zipf-balanced greedy bin-packing, and a Shared Lexical Expert. The updated paper reports 187M ablations and a corrected 300M iso-parameter 8B-token scaling comparison.
Read PaperUnder review
Cite Our Work
@article{
anonymous2026complexitydeep,
title={'{COMPLEXITY}-{DEEP}: Deterministic Lexical Routing with Token-Routed {MLP}'},
author={Anonymous},
journal={Submitted to Transactions on Machine Learning Research},
year={2026},
url={https://openreview.net/forum?id=Jd9jhTnkUy},
note={Under review}
}// ABOUT
Our Mission
Complexity-ML is dedicated to developing efficient and innovative transformer architectures. Our research focuses on making large language models more accessible through deterministic lexical routing, shared expert capacity, and corrected matched-budget scaling.
Zipf-Balanced Routing
A deterministic frequency table assigns tokens to experts with no learned router and no auxiliary load-balancing loss.
Token-Routed MLP
Deterministic lexical routing via Zipf-balanced greedy bin-packing, avoiding learned router collapse and auxiliary balancing losses.
Shared Lexical Expert
A dense shared MLP path preserves common syntax and language patterns while routed experts specialize on lexical partitions.